Editing TMs for training an LLM: How to swap source and target segments ناشر الموضوع: trans-agrar
|
|---|
trans-agrar 
ألمانيا
Local time: 12:39
أنجليزي إلى ألماني
+ ...
Hello you smart people out there.
I'm currently cleansing my TM's for using them to train an LLM. My Cat Tool is MemoQ.
The problem now is that there are a lot of segments, in which source and target are reversed - not just one single segment here and there but a series of many segments. So, I simply must be able to swap them in batches.
MQ doesn't seem to offer a function for this.
1. Using Phyton scripts didn't work, because Phyton continues to have... See more Hello you smart people out there.
I'm currently cleansing my TM's for using them to train an LLM. My Cat Tool is MemoQ.
The problem now is that there are a lot of segments, in which source and target are reversed - not just one single segment here and there but a series of many segments. So, I simply must be able to swap them in batches.
MQ doesn't seem to offer a function for this.
1. Using Phyton scripts didn't work, because Phyton continues to have Path issues on my machine and I'm unable to delete those two Phyton files that seem to cause the issue.
2. Notepad: How to tell Notepad to detect any German words in target segments.
3. I tried Olifant, but I don't manage to use the Swap function based on what I learn from the Help desk. Besides, it doesn't seem to provide a batch function (e.g. swap all marked segments).
4. ChatGPT tells me all kinds of bla bla bla.
5.Can anybody say whether OmegaT is a real option for this?
6. Any other experience out there?
There must be some solution....
Appreciate your thoughts
Thanks
Barbara ▲ Collapse
| | | | Dan Lucas
المملكة المتحدة
Local time: 11:39
عضو (2014)
ياباني إلى أنجليزي
I don't use MemoQ, but I can imagine exporting this as a TMX, exporting that as an Excel file or maybe as "Wordfast TM file" as described in this thread, then opening it in Excel and putting source and target languages in two columns. Then I would write some VBA to step through each row, and swap them (putting the output in columns fou... See more I don't use MemoQ, but I can imagine exporting this as a TMX, exporting that as an Excel file or maybe as "Wordfast TM file" as described in this thread, then opening it in Excel and putting source and target languages in two columns. Then I would write some VBA to step through each row, and swap them (putting the output in columns four and five or something) when required.
But how would you indicate which segments need to be reversed? Unless you can come up with a foolproof way of determining whether the text in the source column is English or German, you'd have to make a decision for every unit in the TM. For dozens of units, that may not be a problem, but for thousands of units...? (This might work in theory, but in practice it may not.)
With all due respect for your ambition, this task would require some skill in coding. On the other hand, ChatGPT could probably write you some useful VBA code provided that you can describe exactly what you want and how to get it. You'd also have to be familiar with using the VBA editor in Excel.
Regards,
Dan
[Edited at 2024-11-28 21:18 GMT] ▲ Collapse
| | | | Stepan Konev
الاتحاد الروسي
Local time: 14:39
أنجليزي إلى روسي
| Swap single segment | Nov 29 |
I don't know how to do that in batch mode, but you can try the below AHK script to swap single segments in the memoQ TM editing mode:
f11::
Send, ^a
Sleep 30
Send, ^x
Sleep 30
Send, {tab}
Sleep 100
Send, ^{PgUp}
Sleep 100
Send, ^v
Sleep 30
Send, ^+{PgDn}
Sleep 100
Send, ^x
Sleep 30
Send, {tab}
Sleep 100
Send, ^v
Return
How to use:
1) Run the script.
2... See more I don't know how to do that in batch mode, but you can try the below AHK script to swap single segments in the memoQ TM editing mode:
f11::
Send, ^a
Sleep 30
Send, ^x
Sleep 30
Send, {tab}
Sleep 100
Send, ^{PgUp}
Sleep 100
Send, ^v
Sleep 30
Send, ^+{PgDn}
Sleep 100
Send, ^x
Sleep 30
Send, {tab}
Sleep 100
Send, ^v
Return
How to use:
1) Run the script.
2) Put the cursor anywhere in the source or target part of the segment you want to swap
3) Press F11.
(I assume you know how to use AHK and create scripts.) ▲ Collapse
| | | |
Open the tmx in tmx edit mode. Enter an expression with typical words for one of the languages in the Find field of the Find dialogue. E.g.: the|left|at|…
Filter the segments. Export the filtered segments. Then remove them.
Open the exported segments in a new project. Save as tab-delimited. Open with Modern CSV or any other TSV handler. Swap the columns.
Import swapped columns in CafeTran Espresso, save as tmx.
Note: In the first step you ... See more Open the tmx in tmx edit mode. Enter an expression with typical words for one of the languages in the Find field of the Find dialogue. E.g.: the|left|at|…
Filter the segments. Export the filtered segments. Then remove them.
Open the exported segments in a new project. Save as tab-delimited. Open with Modern CSV or any other TSV handler. Swap the columns.
Import swapped columns in CafeTran Espresso, save as tmx.
Note: In the first step you can also filter on spelling errors. But you will have to add a lot of words from the correct target language to user.dic. Unless you already have such a list from memoQ.
Filtering on German source segments:
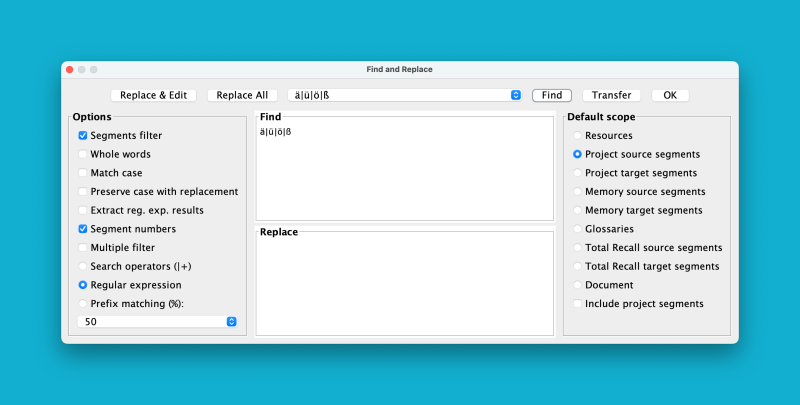 " rel="nofollow">08.03.45@2x"> " rel="nofollow">08.03.45@2x">
[Edited at 2024-11-29 07:04 GMT] ▲ Collapse
| | |
|
|
|
| Here is a potential solution | Nov 30 |
Hi Barbara,
See below a potential solution for a similar situation I had:
1. Assuming that your languages are English and German, use Olifant to mark all wrong German segments in the English part by searching for all German specific characters, e.g. lower and upper case characters with umlaut etc.
2. Export the marked segments in a tmx file.
3. Delete marked segments from tmx file.
4. Open the exported wrong tmx file and, with Notepad++ or Emeditor, an... See more Hi Barbara,
See below a potential solution for a similar situation I had:
1. Assuming that your languages are English and German, use Olifant to mark all wrong German segments in the English part by searching for all German specific characters, e.g. lower and upper case characters with umlaut etc.
2. Export the marked segments in a tmx file.
3. Delete marked segments from tmx file.
4. Open the exported wrong tmx file and, with Notepad++ or Emeditor, and swap the languages through a third language, i.e. change English to Greek, German to English and Greek to German in the segments section only.
5. Fix the source language i, the tmx header.
6. Import the extracted and fixed tmx to the tmx you have deleted the wrong segments.
Good luck!
Kyriaki ▲ Collapse
| | | | trans-agrar
ألمانيا
Local time: 12:39
أنجليزي إلى ألماني
+ ...
بادئ الموضوع | Thank you everybody | Dec 2 |
Dear colleagues,
thank you all for putting your heads into this. And especially thanks to Kyriaki for your advice. This worked eventually for me - at last after so many trials and errors.
So I sucessfully marked a selection, exported it and swapped the languages and carried out the delete/import processes as described. Thanks for this.
There is still a minor hitch though: I don't manage to flag an Olifant selection in a batch procedure. This time I marked 64 entries one... See more Dear colleagues,
thank you all for putting your heads into this. And especially thanks to Kyriaki for your advice. This worked eventually for me - at last after so many trials and errors.
So I sucessfully marked a selection, exported it and swapped the languages and carried out the delete/import processes as described. Thanks for this.
There is still a minor hitch though: I don't manage to flag an Olifant selection in a batch procedure. This time I marked 64 entries one by one as I don't seem to find the "batch flag" function. I'm using Olifant 3.0.8.
Thanks again to everybody. Really grateful for your ideas.
Barbara ▲ Collapse
| | | |
It is good to hear that you have found a solution. Can you tell us which MT system you are training?
| | | | trans-agrar
ألمانيا
Local time: 12:39
أنجليزي إلى ألماني
+ ...
بادئ الموضوع
Hello Hans,
I did the first trial with Kantan. But at the time, my memories were not cleansed yet. To suit, the result was really discouraging. There wasn't a single coherent sentence. I might try Kantan again, once I've sorted out the relevant memories. Another idea was to try Globalese, but this has now been purchased by MemoQ and has become unaffordable for a freelance translator. Yet, it's one step at a time right now. Sorting my memories successfully is the first stopover in th... See more Hello Hans,
I did the first trial with Kantan. But at the time, my memories were not cleansed yet. To suit, the result was really discouraging. There wasn't a single coherent sentence. I might try Kantan again, once I've sorted out the relevant memories. Another idea was to try Globalese, but this has now been purchased by MemoQ and has become unaffordable for a freelance translator. Yet, it's one step at a time right now. Sorting my memories successfully is the first stopover in this journey. The next is to complete the meta data in my termbases. After that I embark on the training adventure.
Cheers
Barbara ▲ Collapse
| | |
|
|
|
Stepan Konev
الاتحاد الروسي
Local time: 14:39
أنجليزي إلى روسي
| trans-agrar
ألمانيا
Local time: 12:39
أنجليزي إلى ألماني
+ ...
بادئ الموضوع | Scripting in Olifant | Dec 4 |
Thanks Stepan for the Opus Cat tool. I'll look at it nearer the time.
Meanwhile I've been trying to use Olifant coding to speed up my selection marking processes.
The following script should list all segments between the key no. 1500 and 2000. But something is wrong, because my list does start at 1500 but then runs to infinity. Can anybody find out what is wrong?
[Key]
| | | | | Size, Plus Tools, Wordfast Anywhere | 09:05 |
trans-agrar wrote:
Hello you smart people out there.
I'm currently cleansing my TM's for using them to train an LLM. My Cat Tool is MemoQ.
Barbara
Hello, I came to this very late. I agree Kyriaki's method is the simplest, once listed export, remove, reverse, feed back in.
Regarding the set of tools:
If your TM is small, Wordfast Anywhere has an immense set of tools to work on TM.
If your TM is big I recommend Plus Tools. It's a free tool actively developed by Yves Champollion. It can handle TMs bigger than 1 million lines. No need for a beefy computer, it's coded to work directly on disk, so no need for 64 GB of RAM.
As Yves welcomes feedback, if you are performing actions that other professionals will likely need to execute too, he might add functionalities in the tool (he ultimately decides what goes in or not). Try it here https://www.wordfast.net/PlusTools/ (accept the browser warnings, the site is legit).
I tried Kantan back in the day (I have a video on it), nice tool!
My bests,
Philippe
| | | | لم يتم تعيين مشرف خاص بهذا المنتدى للإبلاغ عن انتهاكات لقواعد الموقع أو الحصول على مساعدة، يرجى الاتصال بـ العاملين في الموقع » Editing TMs for training an LLM: How to swap source and target segments | Trados Studio 2022 Freelance | The leading translation software used by over 270,000 translators.
Designed with your feedback in mind, Trados Studio 2022 delivers an unrivalled, powerful desktop
and cloud solution, empowering you to work in the most efficient and cost-effective way.
More info » |
| | Wordfast Pro | Translation Memory Software for Any Platform
Exclusive discount for ProZ.com users!
Save over 13% when purchasing Wordfast Pro through ProZ.com. Wordfast is the world's #1 provider of platform-independent Translation Memory software. Consistently ranked the most user-friendly and highest value
Buy now! » |
|
| | | | X Sign in to your ProZ.com account... | | | | | |








